Je suis actuellement Data Scientist dans une jeune start-up de l’AgriTech, nommée “Fruits!”, qui cherche à développer des solutions innovantes pour la récolte des fruits. Notre objectif est de préserver la biodiversité des fruits en créant des robots cueilleurs intelligents, capables de traiter chaque espèce de manière spécifique.
Dans un premier temps, pour sensibiliser le grand public à la biodiversité des fruits et tester une première version de notre moteur de classification des images, nous avons décidé de lancer une application mobile. Cette application permettra aux utilisateurs de prendre en photo un fruit et d’obtenir des informations détaillées à son sujet.
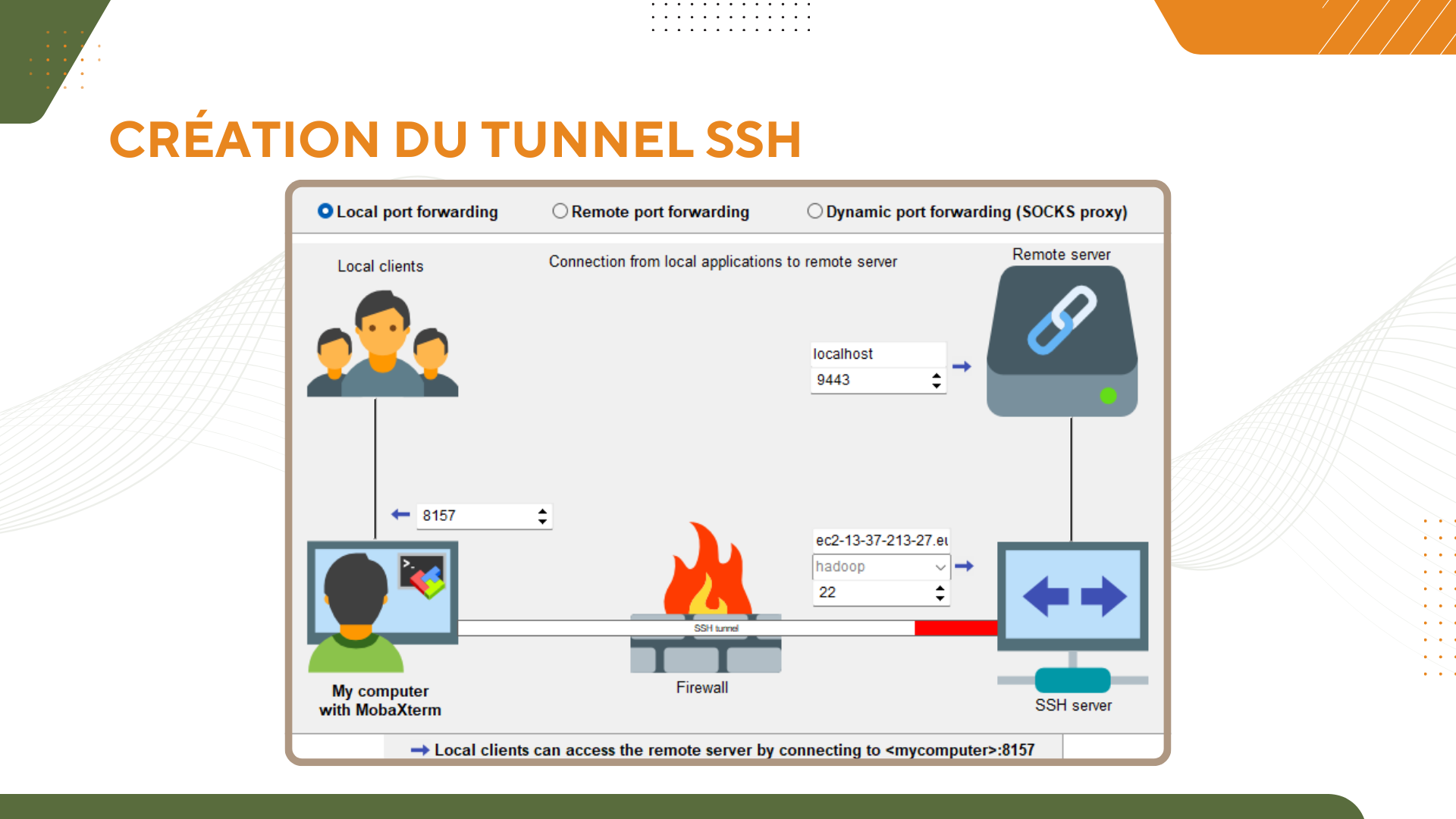
Le développement de cette application mobile représente également une étape cruciale dans la construction de notre architecture Big Data. Mon collègue Paul m’a indiqué qu’un alternant qui vient de quitter l’entreprise avait déjà testé une première approche en utilisant un environnement Big Data AWS EMR, à partir d’un jeu de données constitué d’images de fruits et des labels associés. Je vais m’appuyer sur son travail pour construire les premières briques de notre chaîne de traitement des données.
Ma mission consiste à m’approprier les travaux de l’alternant et à compléter la chaîne de traitement. Il n’est pas encore nécessaire d’entraîner un modèle, mais il est crucial de préparer une infrastructure scalable capable de gérer un volume croissant de données.
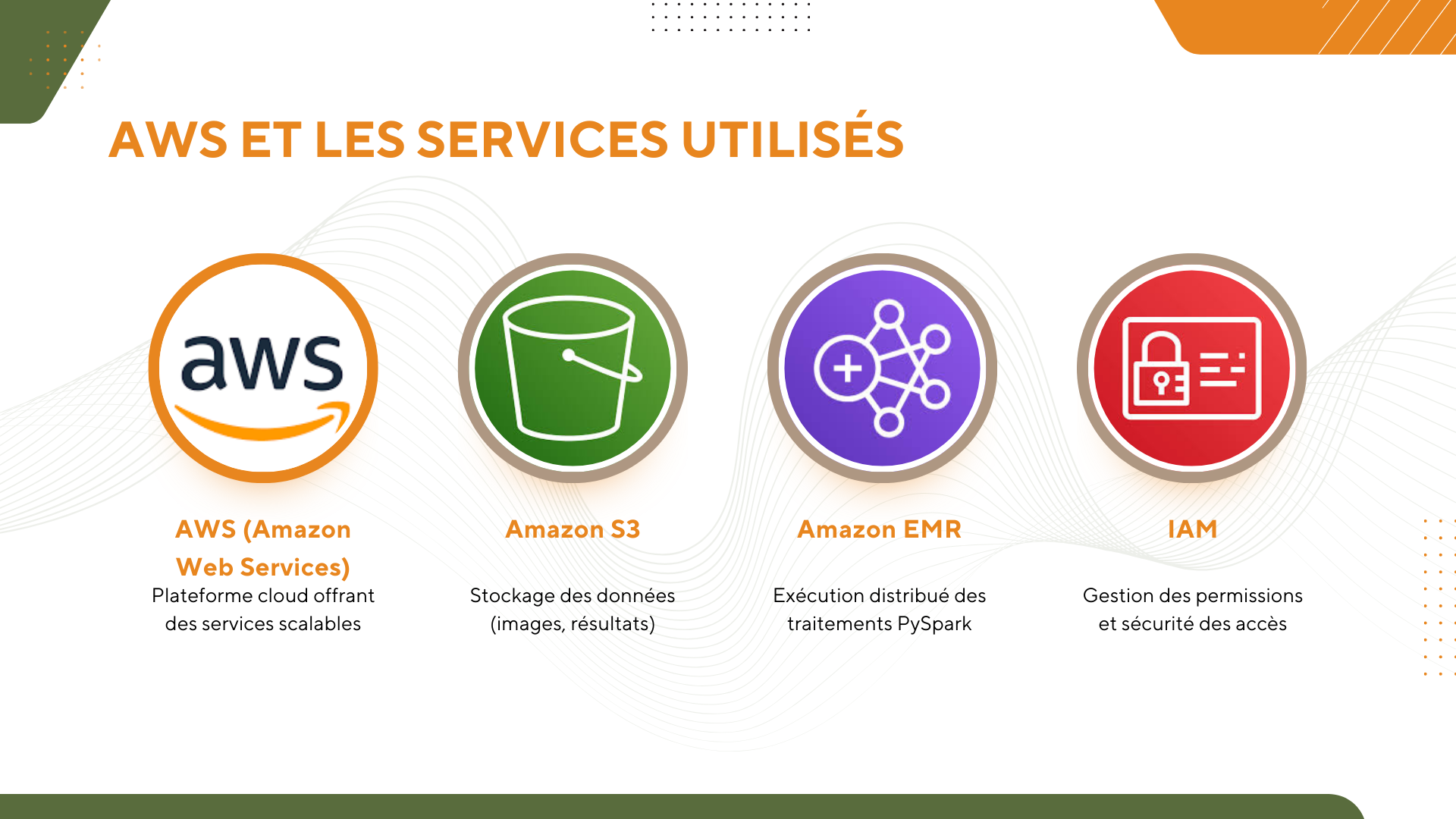
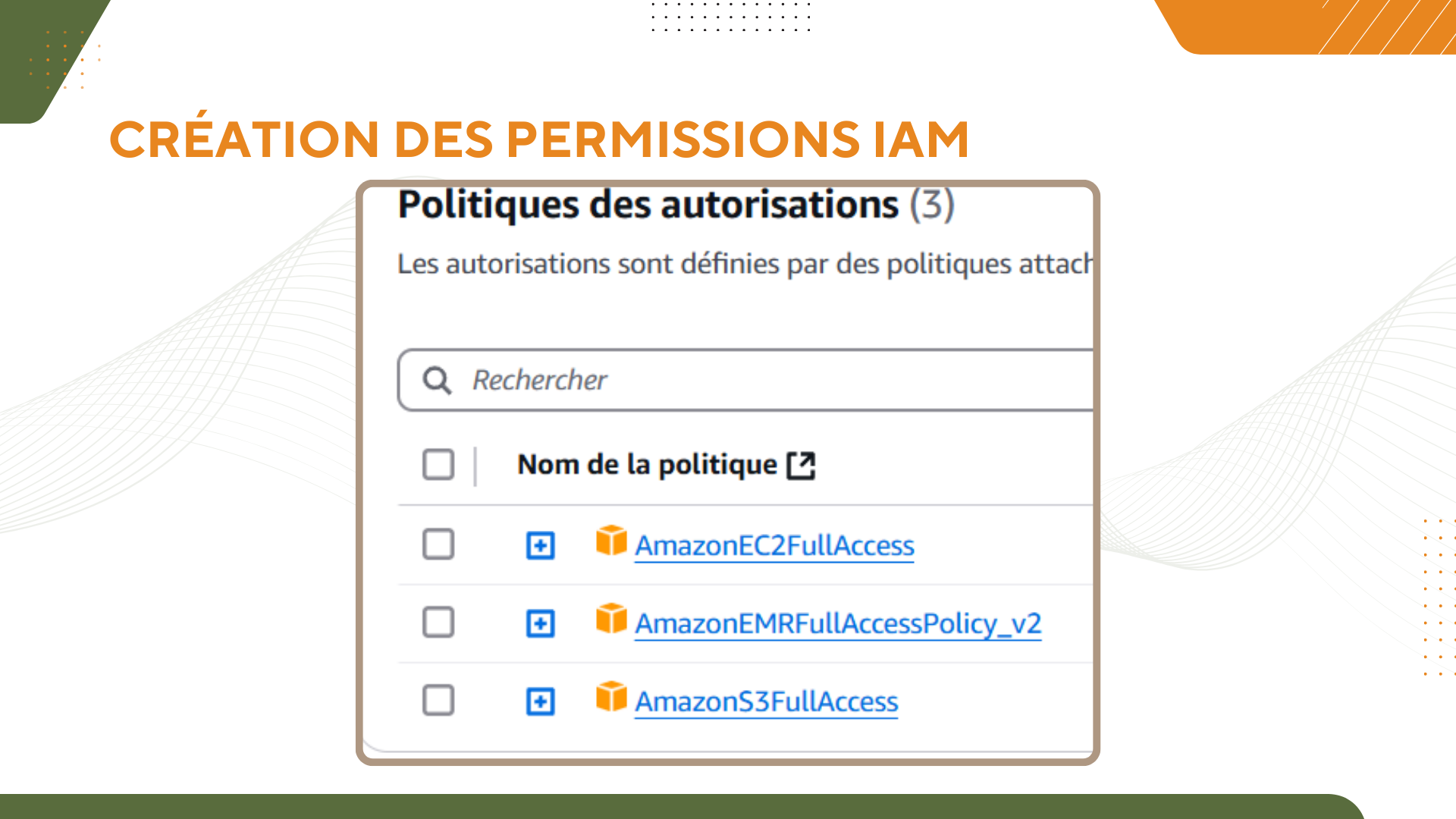
Dans le cadre de cette mission, je vais continuer à développer des scripts en PySpark, en utilisant le cloud AWS et son infrastructure Big Data, y compris EMR, S3, et IAM. Je dois également :
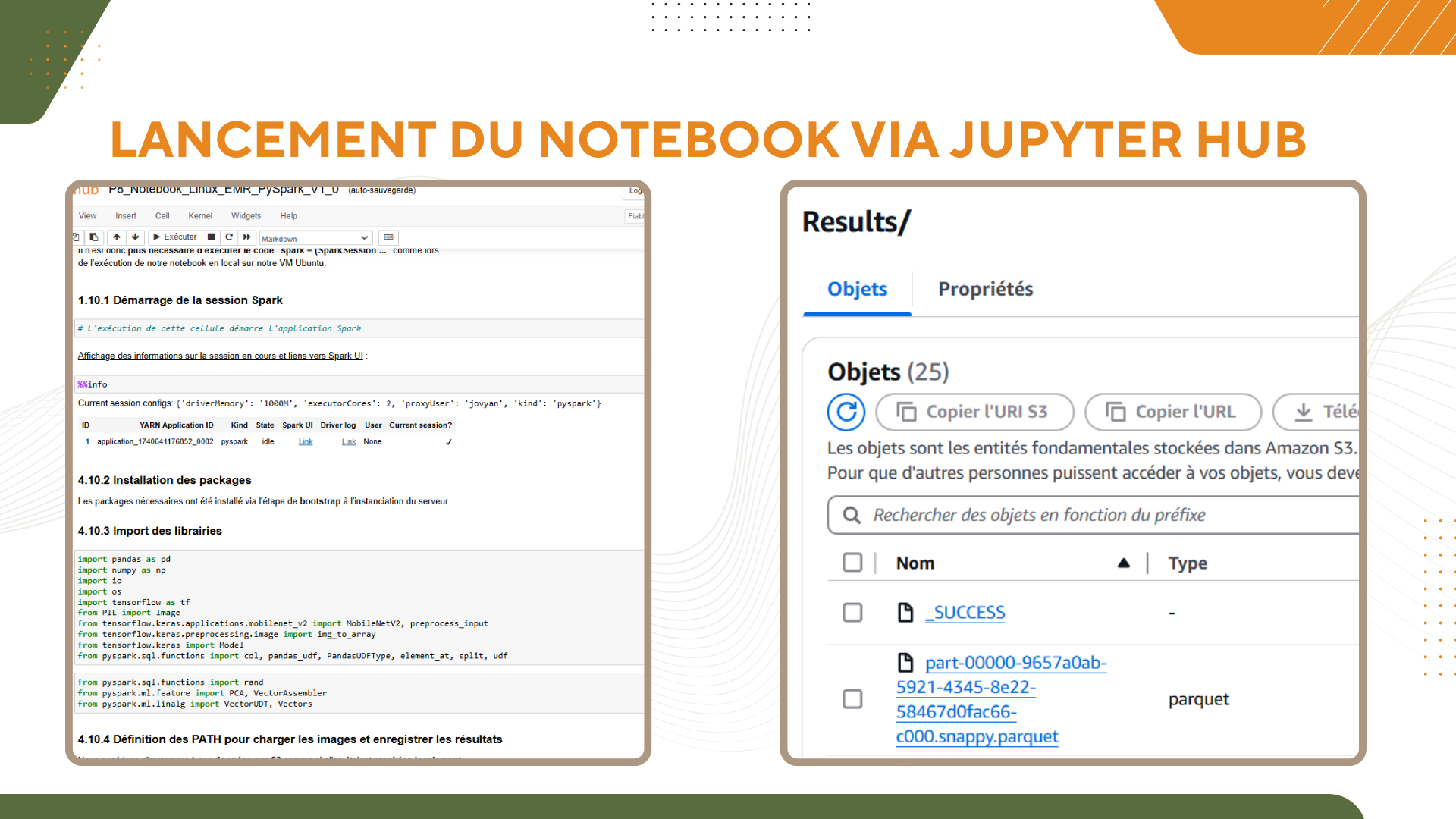
- Mettre en place une instance EMR opérationnelle et expliquer en détail le script PySpark, en ajoutant deux éléments essentiels :
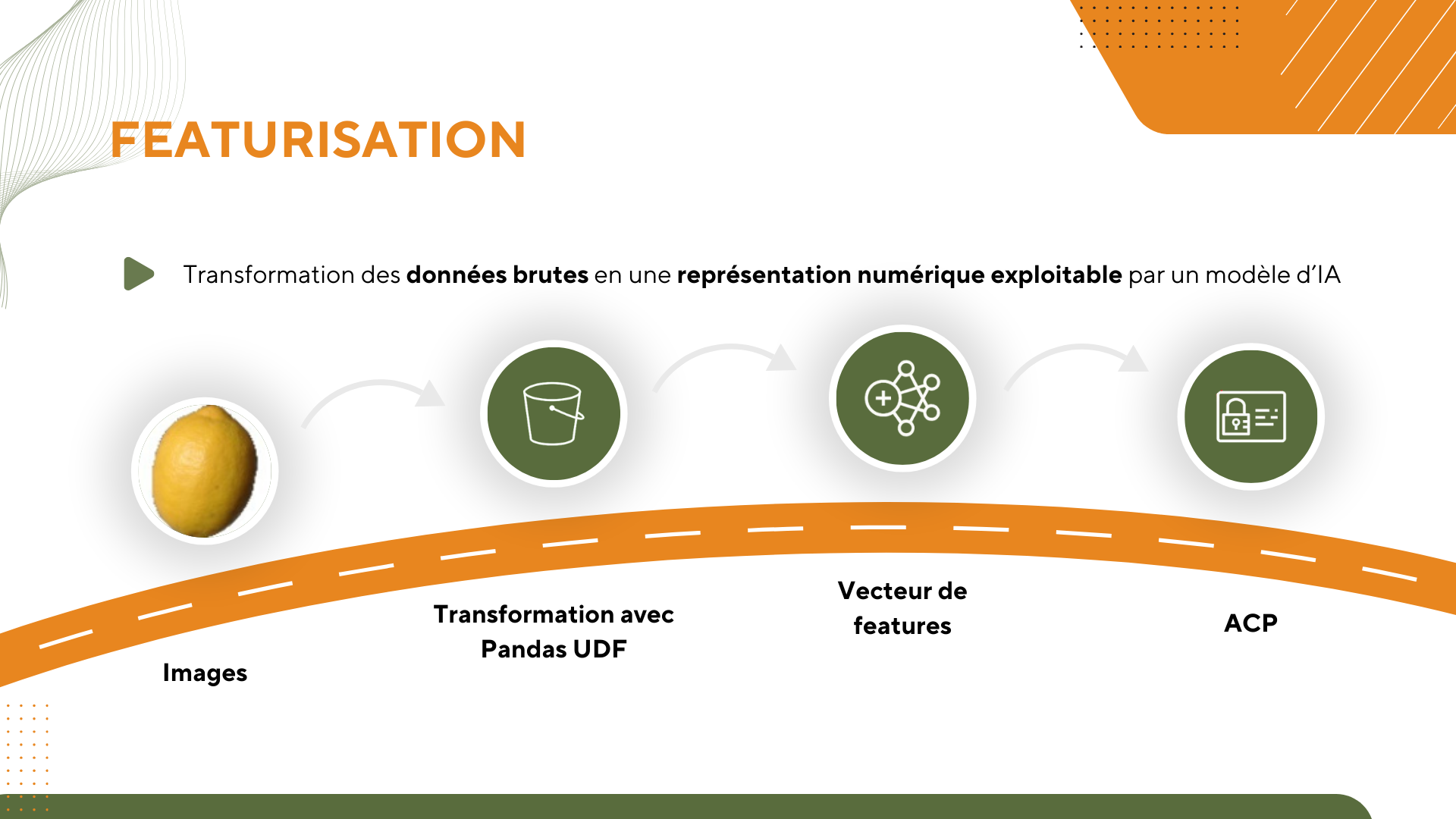
- Un traitement de diffusion des poids du modèle TensorFlow sur les clusters (broadcast des “weights” du modèle), un point omis par l’alternant.
- Une étape de réduction de dimension de type PCA en PySpark.
- Veiller au respect des contraintes du RGPD, en s’assurant que les serveurs utilisés sont situés sur le territoire européen.
Je vais également effectuer un retour critique sur cette solution, afin de décider si elle est viable pour une généralisation future. Il est important de noter que l’utilisation d’une architecture Big Data de type EMR peut engendrer des coûts. Par conséquent, je veillerai à maintenir l’instance EMR opérationnelle uniquement pour les tests et les démonstrations.
Je suis motivé à relever ce défi et à contribuer à l’ambition de “Fruits!” de préserver la biodiversité tout en développant des technologies de pointe pour l’agriculture.